어플리케이션 레벨의 입장에서, raw string 형태의 SQL은 여간 귀찮은 일이 아닐 수가 없다. 수많은 객체 간의 작업, 또는 함수와 콜백 간의 인터랙션이 주가 되는 소스 코드에서, raw string으로 되어 있는 쿼리 문자열은 가독성에 문제를 주기도 하고, 테이블이 alter되거나 데이터베이스 엔진을 마이그레이션했다면 쿼리 문자열들을 하나하나 찾아 수정해 주어야 하는 문제점도 있다.
한가지 예를 들어보자. tbl_users라는 테이블에 사용자에 관련된 몇가지 컬럼들이 있어서, 특정 나이에 해당하는 사용자들의 리스트를 반환하는 함수를 작성한다고 가정하면, 아래와 같은 코드가 나올 수 있다.
위 코드는 그리 문제가 없어 보이지만, tbl_users 테이블에 대한 쿼리를 다루는 곳이 프로젝트 전체에 걸쳐 10군데가 넘는다고 생각해 보자.
- 테이블이 alter되어 email 컬럼이 user_email이라는 이름으로 변경되었다면, '이름 변경'이라는 단순한 작업임에도 불구하고 해당 테이블을 사용하는 쿼리의 갯수만큼 작업 공수가 높아진다.
- 데이터베이스 서버를 마이그레이션한다면, 예를 들어 PostgreSQL을 사용하던 데이터베이스를 MySQL로 옮긴다면 쿼리를 수정해야 할 필요가 있다.
ORM
ORM은 Object Relation Mapping의 약자다. ORM은 RDB의 테이블 구조와 객체지향 프로그래밍 방법론에서의 객체가 꽤 많이 닮아 있다는 것에서 출발한다. 테이블에서 하나의 레코드는 하나의 객체와 매핑되고, 하나의 열과 타입은 객체의 필드와 타입으로 매핑할 수 있다. 결론적으로 ORM은 쿼리와 쿼리의 결과를 각각 string과 Map으로 관리하지 않고, 메소드와 객체로 이루어진 list로 관리하자는 것이다. 이것도 코드로서 예시를 들어 보겠다.
객체지향 표현 방식 중 하나인 클래스로 스키마를 매핑하고, 특별한 메소드를 이용해 쿼리하여 객체로 이루어진 리스트를 얻어온다. 문자열 형태의 SQL을 사용할 때에 비하면, 어플리케이션과 데이터베이스 간의 이질감이 줄어들었다. 그림으로 표현하면 아래와 같다.
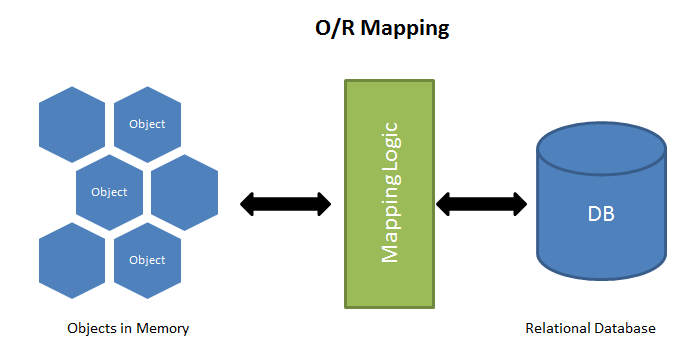
객체 단위로 쿼리를 생성하고, ORM 라이브러리는 이를 raw string SQL로 변환하여 실제로 쿼리를 수행한다. ORM 라이브러리는 데이터베이스를 제공하는 vendor마다 어떤 방식으로 SQL을 작성해야할 지를 알고 있기 때문에, ORM은 데이터베이스 액세스에 대한 추상화 레벨을 높일 수 있는 가장 쉬운 방법이다. 그러나 ORM은 매우 많은 논쟁을 끌고 다니는 기술이다. 이는 Should I or should I not use ORM?이나 마틴 파울러의 ORMHate, Why we don't use ORM등의 글을 읽어보면 도움이 될 것 같다.